JS 中,字符串转数值的方式有以下 9 种:
- parseInt()
- parseFloat()
- Number()
- Double tilde (~~) Operator
- Unary Operator (+)
- Math.floor()
- Multiply with number
- The Signed Right Shift Operator(>>)
- The Unsigned Right Shift Operator(>>>)
这几种方式对运行结果的差异,如下表所示:
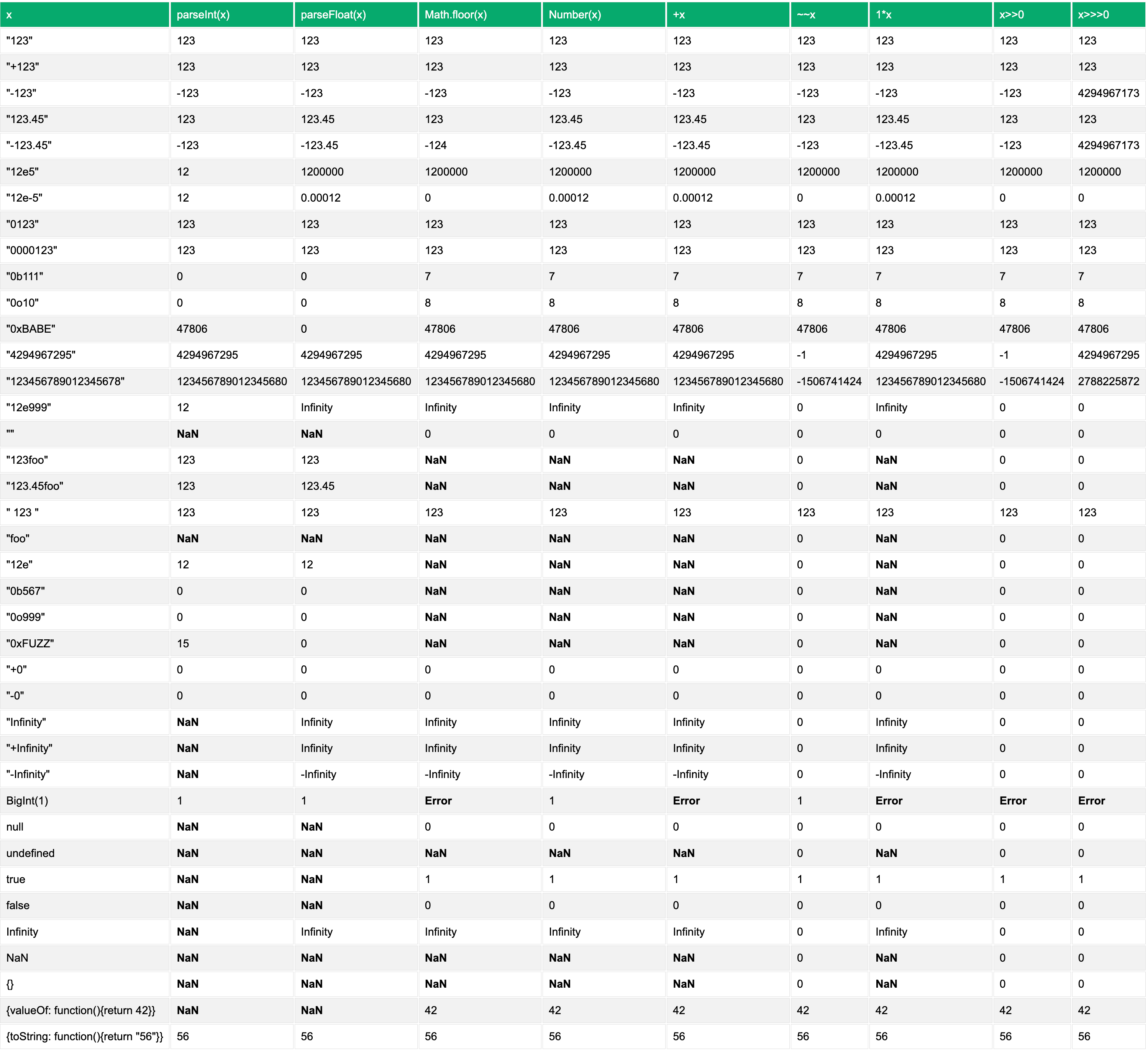
除了运行结果上的存在差异之外,这些方法在性能上也存在着差异。在 NodeJS V8 环境下,这几个方法微基准测试的结果如下:
1 | parseInt() x 19,140,190 ops/sec ±0.45% (92 runs sampled) |
可见,parseInt(),parseFloat(),Math.floor() 的效率最低,只有其他运算 2% 左右的效率,而其中又以parseInt()最慢,仅有 1%。
为什么这些方法存在着这些差异?这些运算在引擎层又是如何被解释执行的?接下来将从 V8、JavaScriptCore、QuickJS 等主流 JS 引擎的视角,探究这些方法的具体实现。
首先来看看 parsrInt()。
1. parseInt()
ECMAScript (ECMA-262) parseInt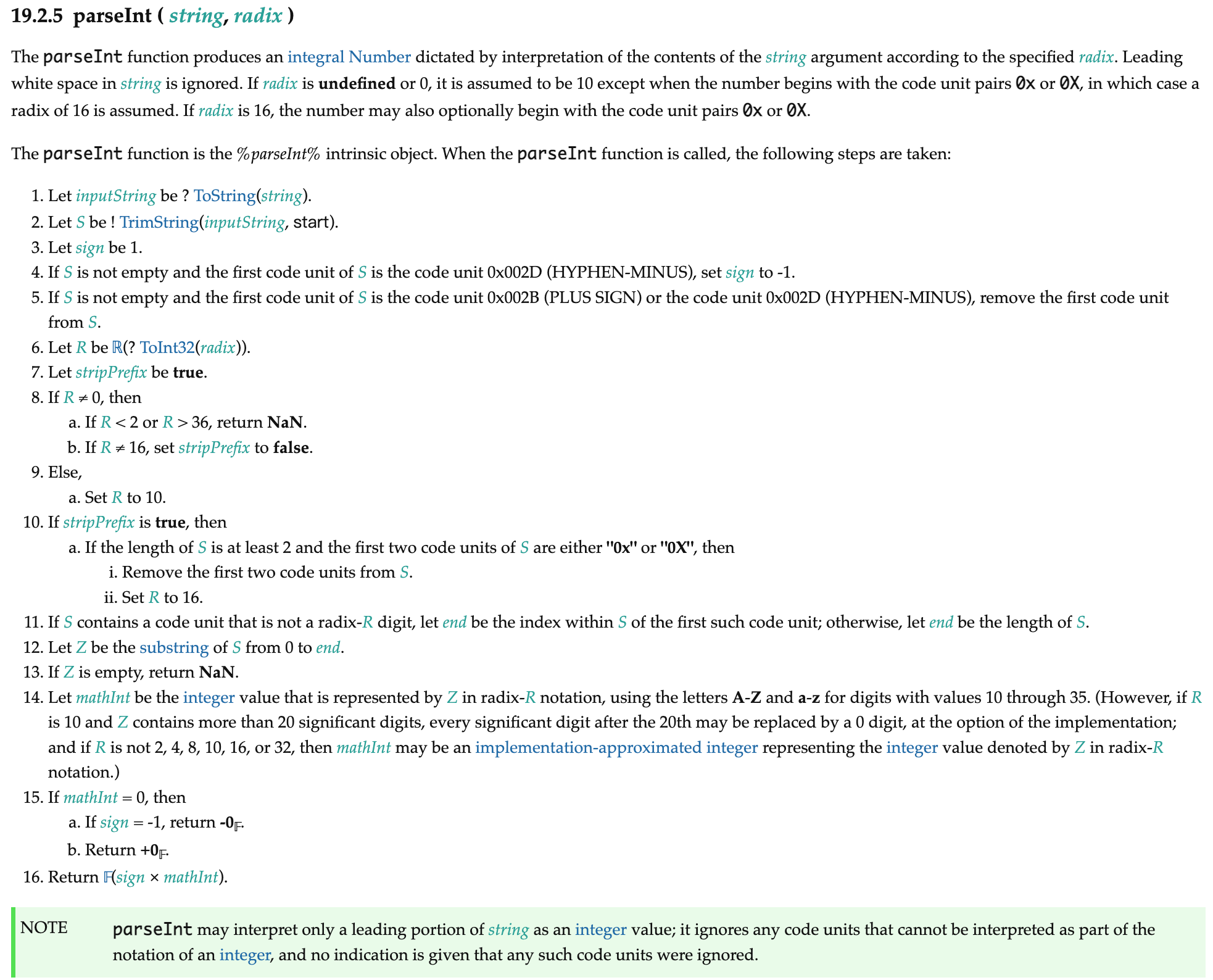
1.1 V8 中的 parseInt()
在 V8 [→ src/init/bootstrapper.cc] 中定义了 JS 语言内置的标准对象,我们可以找到其中关于 parseInt 的定义:
1 | Handle<JSFunction> number_fun = InstallFunction(isolate_, global, "Number", JS_PRIMITIVE_WRAPPER_TYPE, JSPrimitiveWrapper::kHeaderSize, 0, isolate_->initial_object_prototype(), Builtin::kNumberConstructor); |
可以见,Number.parseInt 和全局对象的 parseInt 都是基于 SimpleInstallFunction 注册的,它会将 API 安装到 isolate 中,并将该方法与 Builtin 做绑定。JS 侧调用 pasreInt 即为引擎侧调用 Builtin::kNumberParseInt。
Builtin (Built-in Functions) 是 V8 中在 VM 运行时可执行的代码块,用于表达运行时对 VM 的更改。目前 V8 版本中 Builtin 有下述 5 种实现方式:
- Platform-dependent assembly language:很高效,但需要手动适配到所有平台,并且难以维护。
- C++:风格与runtime functions非常相似,可以访问 V8 强大的运行时功能,但通常不适合性能敏感区域。
- JavaScript:缓慢的运行时调用,受类型污染导致的不可预测的性能影响,以及复杂的 JS语义问题。现在 V8 不再使用 JavaScript 内置函数。
- CodeStubAssembler:提供高效的低级功能,非常接近汇编语言,同时保持平台依赖无关性和可读性。
- Torque:是 CodeStubAssembler 的改进版,其语法结合了 TypeScript 的一些特征,非常简单易读。强调在不损失性能的前提下尽量降低使用难度,让 Builtin 的开发更加容易一些。目前不少内置函数都是由 Torque 实现的。
回到前文 Builtin::kNumberParseInt 这个函数,在 [→ src/builtins/builtins.h] 中可以看到其定义:
1 | // Convenience macro to avoid generating named accessors for all builtins. |
因此这个函数注册的原名是 NumberParseInt,实现在 [→ src/builtins/number.tq] 中,是个基于 Torque 的 Builtin 实现。
1 | // ES6 #sec-number.parseint |
看这段代码前,先科普下 V8 中的几个数据结构:(V8 所有数据结构的定义可以见 [→ src/objects/objects.h])
- Smi:继承自 Object,immediate small integer,只有 31 位
- HeapObject:继承自 Object,superclass for everything allocated in the heap
- PrimitiveHeapObject:继承自 HeapObject
- HeapNumber:继承自 PrimitiveHeapObject,存储了数字的堆对象,用于保存大整形的对象。
我们知道 parseInt 接收两个形参, 即 parseInt(string, radix),此处亦如是。 实现流程如下:
- 首先判断
radix是否没传或者传了 0 或 10,如果不是,那么则不是十进制的转换,就走 runtime 中提供的StringParseInt函数runtime::StringParseInt; - 如果是十进制转换就继续走,判断第一个参数的数据类型。
- 如果是 Smi 或者是没有越界(超 31 位)的 HeapNumber,那么就直接 return 入参,相当于没有转化;否则同样走
runtime::StringParseInt。注意如果这里越界了就会走ChangeInt32ToTagged,其为 CodeStubAssembler 实现的一个函数,会强转 Int32,如果当前执行环境不允许溢出 32 位,那么转换之后的数字就会不合预期。 - 如果是 String,则判断是否是 hash,如果是的就找到对应整型 value 返回;否则依然走
runtime::StringParseInt。
- 如果是 Smi 或者是没有越界(超 31 位)的 HeapNumber,那么就直接 return 入参,相当于没有转化;否则同样走
那么焦点来到了 runtime::StringParseInt。[→ src/runtime/runtime-numbers.cc]
1 | // ES6 18.2.5 parseInt(string, radix) slow path |
这段逻辑比较简单,就不再一行行解读了。值得注意的是,根据标准,如果 radix 不在 2~36 的范围内,会返回 NaN。
1.2 JavaScriptCore 中的 parseInt()
接着我们来看看 JavaScriptCore 中的 parseInt()。
JavaScriptCore 中关于 JS 语言内置对象的注册都在 [→ runtime/JSGlobalObjectFuntions.cpp] 文件中:
1 | JSC_DEFINE_HOST_FUNCTION(globalFuncParseInt, (JSGlobalObject* globalObject, CallFrame* callFrame)) |
WebKit 中的代码注释都很详尽易读,这里也不再解读了。最后,会调用 parseInt,JavaScriptCore 的 parseInt 的实现全放在了 [→ runtime/ParseInt.h] 中,核心代码如下:
1 | ALWAYS_INLINE static bool isStrWhiteSpace(UChar c) |
直接贴出了代码,因为 JavaScriptCore 中的 API 都是严格按照 ECMAScript (ECMA-262) parseInt 标准一步一步按流程实现,可读性和注释也很好,强烈建议读者自己阅读一下,此处不再解读。
1.3 QuickJS 中的 parseInt()
QuickJS 的核心代码都在 [→ quickjs.c] 中,首先是 parseInt 的注册代码:
1 | /* global object */ |
js_parseInt 的实现逻辑如下:
1 | static JSValue js_parseInt(JSContext *ctx, JSValueConst this_val, |
Bellard 大神的代码注释很少,但同时也非常精炼。
至此,本文介绍完了三个引擎下各自 parseInt 的实现,三者都是基于标准的实现,但由于代码风格不同,读起来也像是阅读三个风格不同散文大家的作品。
不过标准和实现,我们可以发现 parseInt 在真正执行字符串转数字这个操作做了非常多的前置操作,如入参合法判断、入参默认值、字符串格式判断与规整化、越界判断等等,最后再交由 runtime 处理。因此,我们不难推出其效率略低的原因。
接下来,我们再简单看看 parseFloat。
2. parseFloat()
ECMAScript (ECMA-262) parseFloat
根据标准,parseFloat 与 parseInt 有两点明显的不同:
- 仅支持一个入参,不支持进制转换
- 返回值支持浮点型
2.1 V8 中的 parseFloat()
V8 中 parseFloat 的相关逻辑都紧挨着 parseInt,这里直接贴出关键实现:
[→ src/builtins/number.tq]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// ES6 #sec-number.parsefloat
transitioning javascript builtin NumberParseFloat(
js-implicit context: NativeContext)(value: JSAny): Number {
try {
typeswitch (value) {
case (s: Smi): {
return s;
}
case (h: HeapNumber): {
// The input is already a Number. Take care of -0.
// The sense of comparison is important for the NaN case.
return (Convert<float64>(h) == 0) ? SmiConstant(0) : h;
}
case (s: String): {
goto String(s);
}
case (HeapObject): {
goto String(string::ToString(context, value));
}
}
} label String(s: String) {
// Check if the string is a cached array index.
const hash: NameHash = s.raw_hash_field;
if (IsIntegerIndex(hash) &&
hash.array_index_length < kMaxCachedArrayIndexLength) {
const arrayIndex: uint32 = hash.array_index_value;
return SmiFromUint32(arrayIndex);
}
// Fall back to the runtime to convert string to a number.
return runtime::StringParseFloat(s);
}
}
[→ src/runtime/runtime-numbers.cc]1
2
3
4
5
6
7
8
9
10
11// ES6 18.2.4 parseFloat(string)
RUNTIME_FUNCTION(Runtime_StringParseFloat) {
HandleScope shs(isolate);
DCHECK_EQ(1, args.length());
Handle<String> subject = args.at<String>(0);
double value = StringToDouble(isolate, subject, ALLOW_TRAILING_JUNK,
std::numeric_limits<double>::quiet_NaN());
return *isolate->factory()->NewNumber(value);
}
因标准中的流程更为简易,因此较 parseInt 而言, parseFloat 更加简单易读。
2.2 JavaScriptCore 中的 parseFloat()
在 JavaScriptCore 中,parseFloat 的逻辑则更加简洁明了:
1 | static double parseFloat(StringView s) |
2.3 QuickJS 中的 parseFloat()
而对比 JavaScriptCore,QuickJS 则短短 12 行:
[→ quickjs.c]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static JSValue js_parseFloat(JSContext *ctx, JSValueConst this_val,
int argc, JSValueConst *argv)
{
const char *str, *p;
JSValue ret;
str = JS_ToCString(ctx, argv[0]);
if (!str)
return JS_EXCEPTION;
p = str;
p += skip_spaces(p);
ret = js_atof(ctx, p, NULL, 10, 0);
JS_FreeCString(ctx, str);
return ret;
}
不过对比之后可以知道,QuickJS 这里之所以短小,是没有做 ASCII 和 8Bit 的兼容。阅读 ECMAScript (ECMA-262) parseFloat 之后可以发现,QuickJS 这里的处理其实没有什么问题,最新的标准中并没有要求解释器要这样的兼容。
3. Number()
ECMAScript (ECMA-262) Number ( value )

3.1 V8 中的 Number()
Number 作为全局对象,定义还是在 [→ src/init/bootstrapper.cc] 中,在前文介绍 Number.parseInt 的注册时已然介绍过,我们回顾下:
1 | Handle<JSFunction> number_fun = InstallFunction( |
这段代码处理注册了 Number 这个对象之外,还初始化了它的原型链,并把构造函数添加到了它的原型链上。构造函数 Builtin::kNumberConstructor 是 Torque 实现的 Builtin,[→ src/builtins/constructor.tq] ,具体实现如下:
1 | // ES #sec-number-constructor |
注释中的 1-6 一一对应着[ECMAScript (ECMA-262) Number ( value )]标准中的流程 1-6,因此本文不再花篇章赘述其实现。需要注意的是,标准中明确说明了 Number 是支持 BigInt 的,各引擎的实现也着重注意了这点,这也证明了我们之前运算对照表中的结果。
3.2 JavaScriptCore 中的 Number()
JavaScriptCore 中的这段代码则缺少注释,但逻辑上与 V8 一模一样,遵循标准:
[→ runtime/NumberConstructor.cpp]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// ECMA 15.7.1
JSC_DEFINE_HOST_FUNCTION(constructNumberConstructor, (JSGlobalObject* globalObject, CallFrame* callFrame))
{
VM& vm = globalObject->vm();
auto scope = DECLARE_THROW_SCOPE(vm);
double n = 0;
if (callFrame->argumentCount()) {
JSValue numeric = callFrame->uncheckedArgument(0).toNumeric(globalObject);
RETURN_IF_EXCEPTION(scope, { });
if (numeric.isNumber())
n = numeric.asNumber();
else {
ASSERT(numeric.isBigInt());
numeric = JSBigInt::toNumber(numeric);
ASSERT(numeric.isNumber());
n = numeric.asNumber();
}
}
JSObject* newTarget = asObject(callFrame->newTarget());
Structure* structure = JSC_GET_DERIVED_STRUCTURE(vm, numberObjectStructure, newTarget, callFrame->jsCallee());
RETURN_IF_EXCEPTION(scope, { });
NumberObject* object = NumberObject::create(vm, structure);
object->setInternalValue(vm, jsNumber(n));
return JSValue::encode(object);
}
3.3 QuickJS 中的 Number()
Number 对象及其原型链的注册代码如下所示:
[→ quickjs.c]1
2
3
4
5
6
7
8
9
10
11
12
13
14void JS_AddIntrinsicBaseObjects(JSContext *ctx)
{
//...
/* Number */
ctx->class_proto[JS_CLASS_NUMBER] = JS_NewObjectProtoClass(ctx, ctx->class_proto[JS_CLASS_OBJECT], JS_CLASS_NUMBER);
JS_SetObjectData(ctx, ctx->class_proto[JS_CLASS_NUMBER], JS_NewInt32(ctx, 0));
JS_SetPropertyFunctionList(ctx, ctx->class_proto[JS_CLASS_NUMBER], js_number_proto_funcs, countof(js_number_proto_funcs));
number_obj = JS_NewGlobalCConstructor(ctx, "Number", js_number_constructor, 1, ctx->class_proto[JS_CLASS_NUMBER]);
JS_SetPropertyFunctionList(ctx, number_obj, js_number_funcs, countof(js_number_funcs));
}
同样的时候,在原型链注册的时候绑上了构造函数 js_number_constructor :
1 | static JSValue js_number_constructor(JSContext *ctx, JSValueConst new_target, |
值得关注的是 QuickJS 追求精简小巧,因此可以自行配置是否支持 BigInt,其余逻辑依然遵循标准。
4. Double tilde (~~) Operator
ECMAScript (ECMA-262) Bitwise NOT Operator

使用 ~ 运算符利用到了标准中的第 2 步,对被计算的值做类型转换,从而将字符串转成数值。这里我们关注这个环节具体是在引擎中的哪个步骤完成的。
4.1 V8 中的 BitwiseNot
首先看看 V8 中对一元运算符的判断:
[→ src/parsing/token.h]
1 | static bool IsUnaryOp(Value op) { return base::IsInRange(op, ADD, VOID); } |
定义在 ADD 和 VOID 范围内的 op,都是一元运算符,具体包括 (可见 [→ src/parsing/token.h]),其中 SUB 和 ADD 定义在二元运算符列表的末端,在 IsUnaryOp 中它们也会命中一元符的判断:
1 | E(T, ADD, "+", 12) |
之后进入语法分析阶段,解析 AST 树的过程中,遇到一元运算符会做相应的处理,先调用 ParseUnaryOrPrefixExpression 之后构建一元运算符表达式 BuildUnaryExpression:
[→ src/parsing/parser-base.h]
1 | template <typename Impl> |
1 | template <typename Impl> |
[→ src/parsing/parser.cc]
1 | Expression* Parser::BuildUnaryExpression(Expression* expression, |
如果字面量是数值型且一元运算符此刻不是 NOT(!),那么会把 Value 会转成 Number,如果是 BIT_NOT 再转成 INT32 进行取反运算。
4.2 JavaScriptCore 中的 BitwiseNot
同样在语法分析生成 AST 阶段,处理到 TILDE(~) 这个 token 后,创建表达式时会做类型转换的工作:
[→ Parser/Parser.cpp]
1 | template <typename LexerType> |
[→ parser/ASTBuilder.h]
1 | ExpressionNode* ASTBuilder::makeBitwiseNotNode(const JSTokenLocation& location, ExpressionNode* expr) |
[→ parser/NodeConstructors.h]
1 | inline BitwiseNotNode::BitwiseNotNode(const JSTokenLocation& location, ExpressionNode* expr) |
[→ parser/ResultType.h]
1 | static constexpr ResultType forBitOp() |
4.3 QuickJS 中的 BitwiseNot
QuickJS 在语法分析阶段,遇到 ~ 这个 token 会调用 emit_op(s, OP_not):
[→ quickjs.c]
1 | /* allowed parse_flags: PF_ARROW_FUNC, PF_POW_ALLOWED, PF_POW_FORBIDDEN */ |
emit_op 会生成 OP_not 字节码操作符,并将源码保存在 fd->byte_code 里。
1 | static void emit_op(JSParseState *s, uint8_t val) |
QuickJS 解释执行的函数是 JS_EvalFunctionInternal,其会调用 JS_CallFree 进行字节码的解释执行,其核心逻辑是调用的 JS_CallInternal 函数。
1 | /* argv[] is modified if (flags & JS_CALL_FLAG_COPY_ARGV) = 0. */ |
可见,解析到 OP_not 时, 如果是整型就直接取反,否则就调用 js_not_slow:
1 | static no_inline int js_not_slow(JSContext *ctx, JSValue *sp) |
js_not_slow 会尝试转整型,转不了就转 -1,转的了就转整型后取反。JS_ToInt32Free 转换逻辑如下:
1 | /* return (<0, 0) in case of exception */ |
对于字符串,会走到 JS_ToNumberFree,之后调用 JS_ToNumberHintFree,涉及到字符串处理的核心逻辑如下:
1 | static JSValue JS_ToNumberHintFree(JSContext *ctx, JSValue val, |
可以转化的用 JS_NewInt32 去处理,否则返回 NaN。
5. Unary Operator (+)
ECMAScript (ECMA-262) Unary Plus Operator

一元运算符加号是笔者最喜欢用的一种字符串转数值的方式,标准中它没有什么花里胡哨的、非常简介明了,就是用来做数值类型转换的。
5.1 V8 中的 UnaryPlus
语法分析阶段同 Double tilde (~~) Operator,此处不再赘述。
5.2 JavaScriptCore 中的 UnaryPlus
语法分析阶段同 Double tilde (~~) Operator,此处不再赘述。
5.3 QuickJS 中的 UnaryPlus
语法分析阶段同 Double tilde (~~) Operator,此处不再赘述。最后依然走到 JS_CallInternal。
[→ quickjs.c]
1 | /* argv[] is modified if (flags & JS_CALL_FLAG_COPY_ARGV) = 0. */ |
可以发现当操作数是 Int 或 Float 时,就直接不处理,和标准中规范的一致。而其他情况就调用 js_unary_arith_slow,若调用过程中遇到异常就走异常逻辑:
1 | static no_inline __exception int js_unary_arith_slow(JSContext *ctx, JSValue *sp, OPCodeEnum op) |
这里的 JS_ToFloat64Free 的内部处理逻辑和和 4.3 时的 JS_ToFloat64Free 一样,不再赘述。js_unary_arith_slow 处理完数值转换之后,若运算符是一元运算加号,则直接返回;否则还会根据运算符再做相应的运算处理,如自增符还需要+1 等。
至此,我们讲解了以下 5 个方法在解释器中的具体实现:
- parseInt()
- parseFloat()
- Number()
- Double tilde (~~) Operator
- Unary Operator (+)
除却以上 5 个数值转换方法之外,还有以下 4 个方法,因篇幅问题本文暂且不再详述:
- Math.floor()
- Multiply with number
- The Signed Right Shift Operator(>>)
- The Unsigned Right Shift Operator(>>>)
字符串转数值各有优劣,使用者可根据自己的需要进行选用,以下是我个人总结的一些经验:
如果返回值只要求整形:
- 追求代码简洁和执行效率,对输入值有一定的把握(无需防御),优先选用 Unary Operator (+)
- 对输入值没有把握,需要做防御式编程,使用 parseInt()
- 需要支持 BigInt, 优先考虑使用 Number() ;如果用 Double tilde (~~) Operator,需要注意 31 位问题。
如果返回值要求浮点型:
- 追求代码简洁和执行效率,对输入值有一定的把握(无需防御),优先选用 Unary Operator (+)
- 对输入值没有把握,需要做防御式编程,使用 parseFloat()
- 需要支持 BigInt,使用 parseFloat()